Scraping¶
Whereas crawling is where we follow links to get a list of URLs of a site, scraping is where we pull out specific elements of pages.
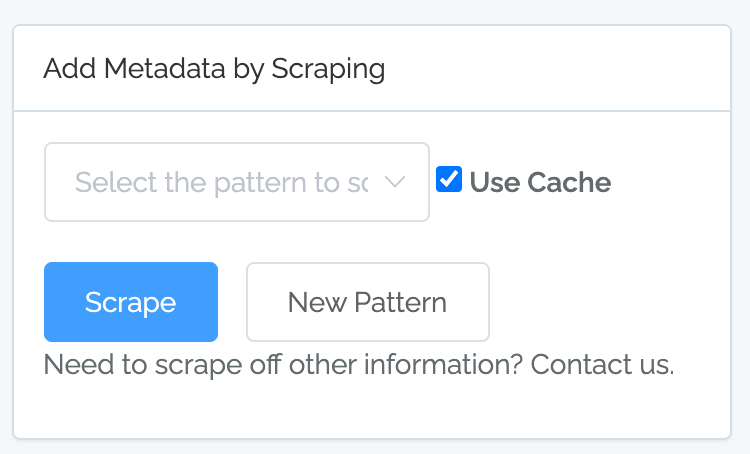
Scraping is accessed on the Assets & Metadata page:
Why?¶
Why might you want to scrape out information? There are three primary reasons:
There’s information on the pages that you don’t have a reasonable means of accessing any other way. One simple case is when you are doing business development, but other times it may just be inconvenient (either technically or politically) to get.
As a unifying means of collecting information across a heterogeneous digital presence, which may span multiple source systems.
As a means of getting multi-values into Content Chimera with minimal fuss (for instance, multiple topics per page).
Common types of patterns¶
Site structure. The basic, default chart in Content Chimera (as well as the deep site structure chart) show structure if URLs are structured meaningfully, which most sites do. That said, some sites do not organize URLs meaningfully. In those cases, you may be able to scrape out pattern (such as from breadcrumbs).
Topical, tagging, and taxonomy information. For many projects you need to know how topics or other taxonomies are applied to content.
Finding known problems. You may either want to scrape out current problems (like bad character encodings) or problems that may occur during a transformation (like Microsoft cruft, which may look fine on the current site have a high probability of introducing problems in a migration).
The presence or distribution of components. You may either be interested in a fairly rough distribution, like how many pages have links to Word documents, or finer grained like what standard components (hero image, regular text, callout text, etc) when templates are using standard components.
Finding versions. There may be components or libraries that you use throughout the site, but you suspect that some are using old versions. This type of information can often be scraped.
Scraping adds new fields for your analysis¶
Instead of just filling one field with one value, Content Chimera generates six fields when you scrape:
First match. The first match of the full pattern. In some cases, your pattern by design only captures one value. In that case, it’s in this field.Example: Breadcrumb 1.
Second match. The second match of the full pattern. Example: Breadcrumb 2.
Third match. The third match of the full pattern. Example: Breadcrumb 3.
Count. The total count of matches. Example: Breadcrumb count.
Test result. In the case of the default “Has” test, this will be “yes” if there was at least one match. Example: Has Breadcrumb.
Full list. This is the comma-separated list of all the matches, up to certain limits. Example: Breadcrumb all.
Scraping common full patterns¶
The global, common patterns are:
Forms. Captures HTML forms.
Tables. Captures HTML tables.
Bad Character Encodings. Captures examples of unusual characters that naturally occur when character encodings have been improperly dealt with in the past (for instance, in a past migration). Bad Character Encodings only works for content in English.
Microsoft cruft. Captures common Microsoft Office styling. Office styling is attempting to retain the look from the original Word document, which can cause problems when moved into new templates.
PDF Page Count. Counts the number of pages in each PDF.
Scraping a common pattern is easy. Just select it from the list and click “Scrape”.
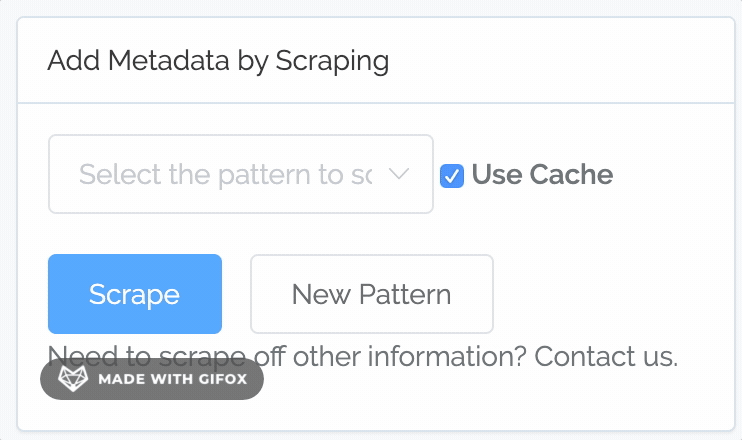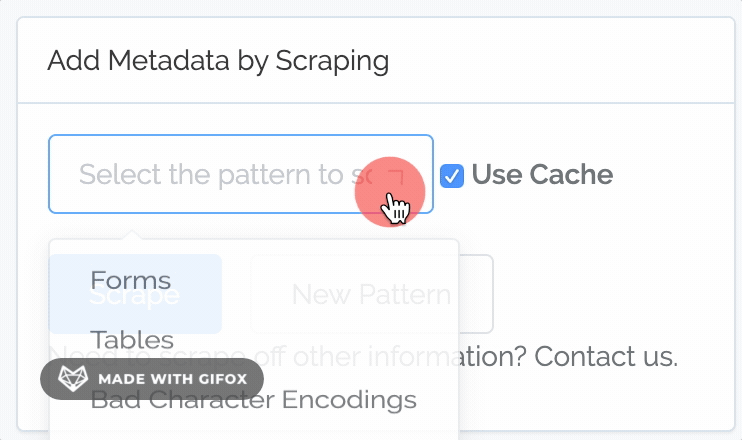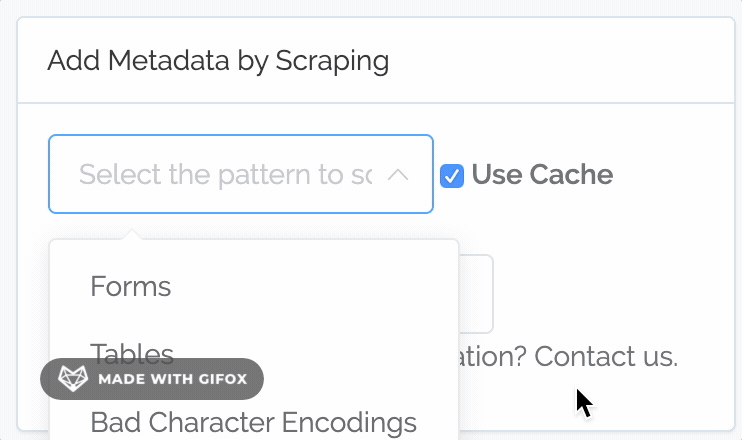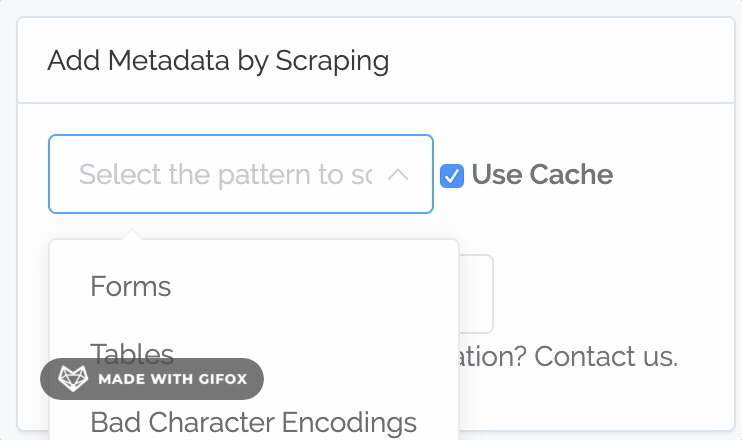
Note
Content Chimera keeps a cache of all the sites that you crawl. By default, Content Chimera will use that cache rather than requesting from the web servers again.
Scraping all selected patterns¶
Start by scraping each pattern one by one. After you have already scraped a patterns, they will appear in the “Current Patterns for This Extent” section on the Assets page).
To scrape all these patterns all at once, just click on Scrape All (which will always use the cache).
What is a full pattern?¶
When you scrape, you are defining patterns to scrape from the content. A pattern consists of three elements:
The scope. This is fundamentally where to even look for what you’re trying to scrape. For instance, it can be “All PDFs” or it can be as specific as a particular element on a web page (usually leveraging xpath).
The pattern. The pattern is exactly what part of the scope to extract (usually leveraging regex).
The test. This is a final evaluation, which is usually simply “Has” (see “Scraping adds new fields for your analysis” above).
Note that for predefined patterns you do not need to really understand the above.
Defining and scraping new full patterns¶
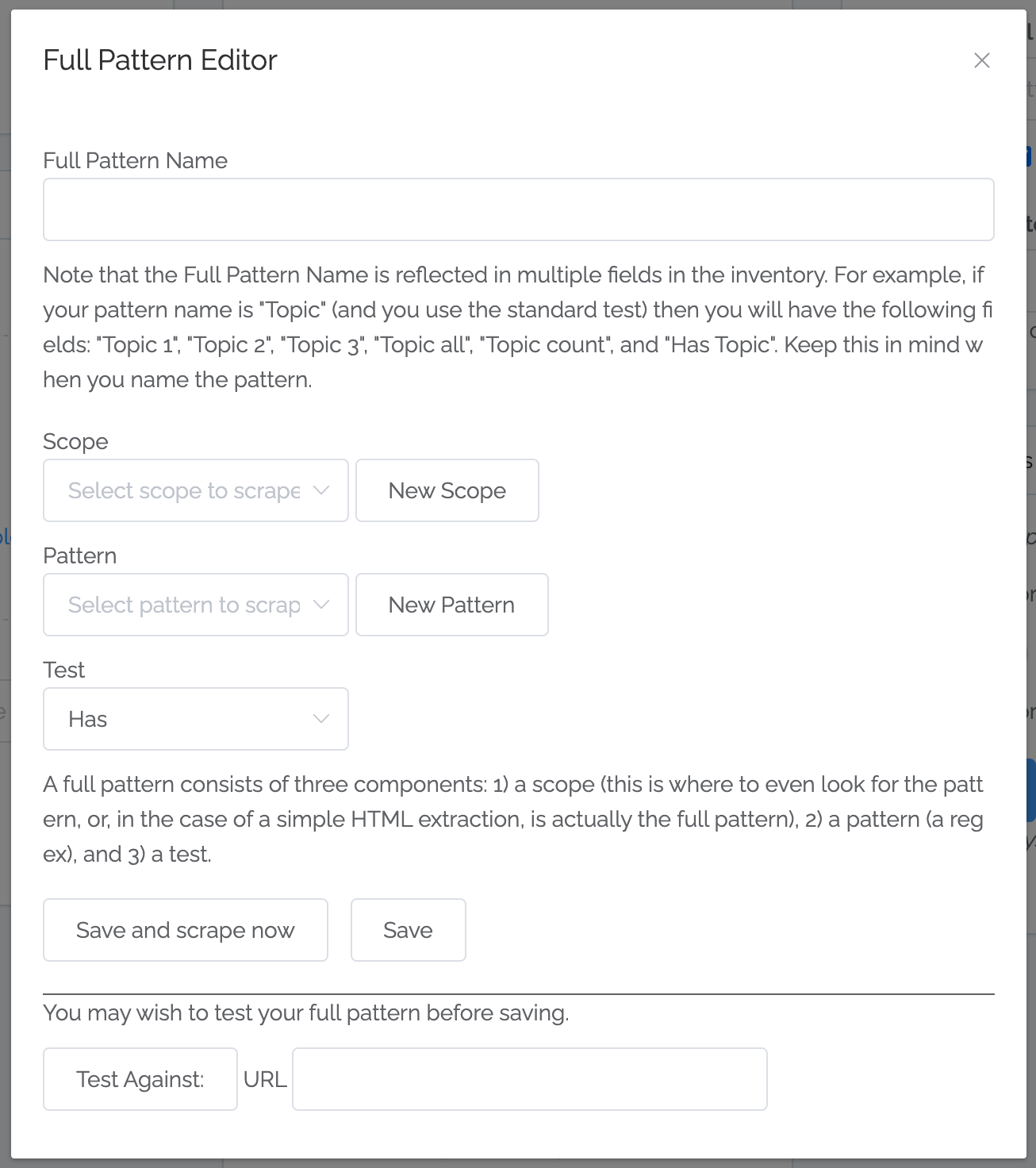
The exact process is perhaps best described with an example (see below), but for reference these are the steps:
Go to the Assets & Metadata page.
Click on New Pattern.
Give your pattern a name.
Define the scope (or use an existing one). See description below.
Define the pattern (or use an exiting one). See description below.
In virtually all cases, leave the default Has test selected.
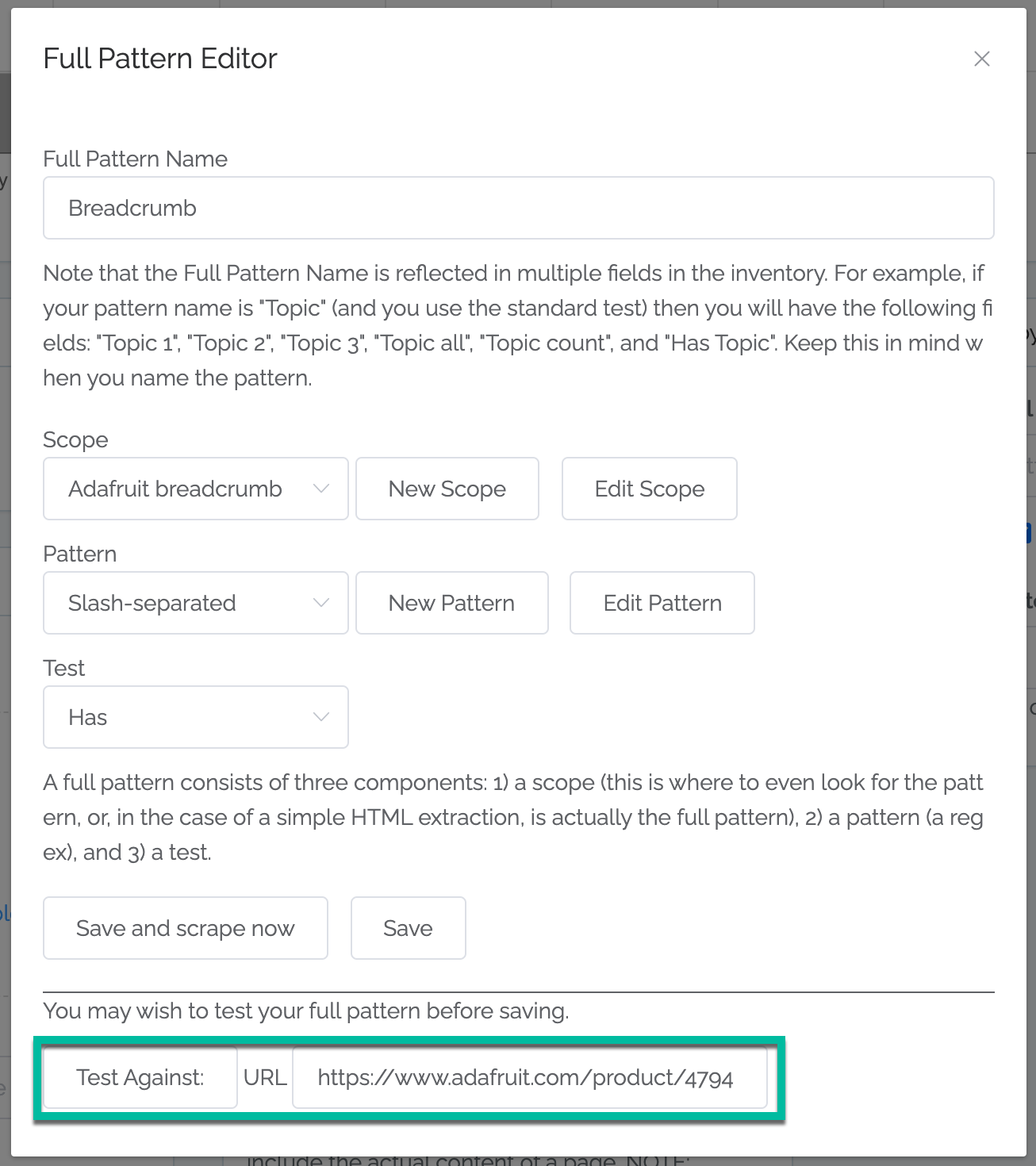
Test by putting a URL next to the Test Against button and then click that button (there is a delay before the results appear).
When satisfied that your new full pattern is working, click on “Save and scrape now”.
Note
When you select a scope or pattern in the pulldown of existing ones, sometimes an Edit button will appear. Edit only appears for patterns that are not global (since you cannot modify those). If you want to make a change to a global one, then you can create your own from scratch.
Defining a scope¶
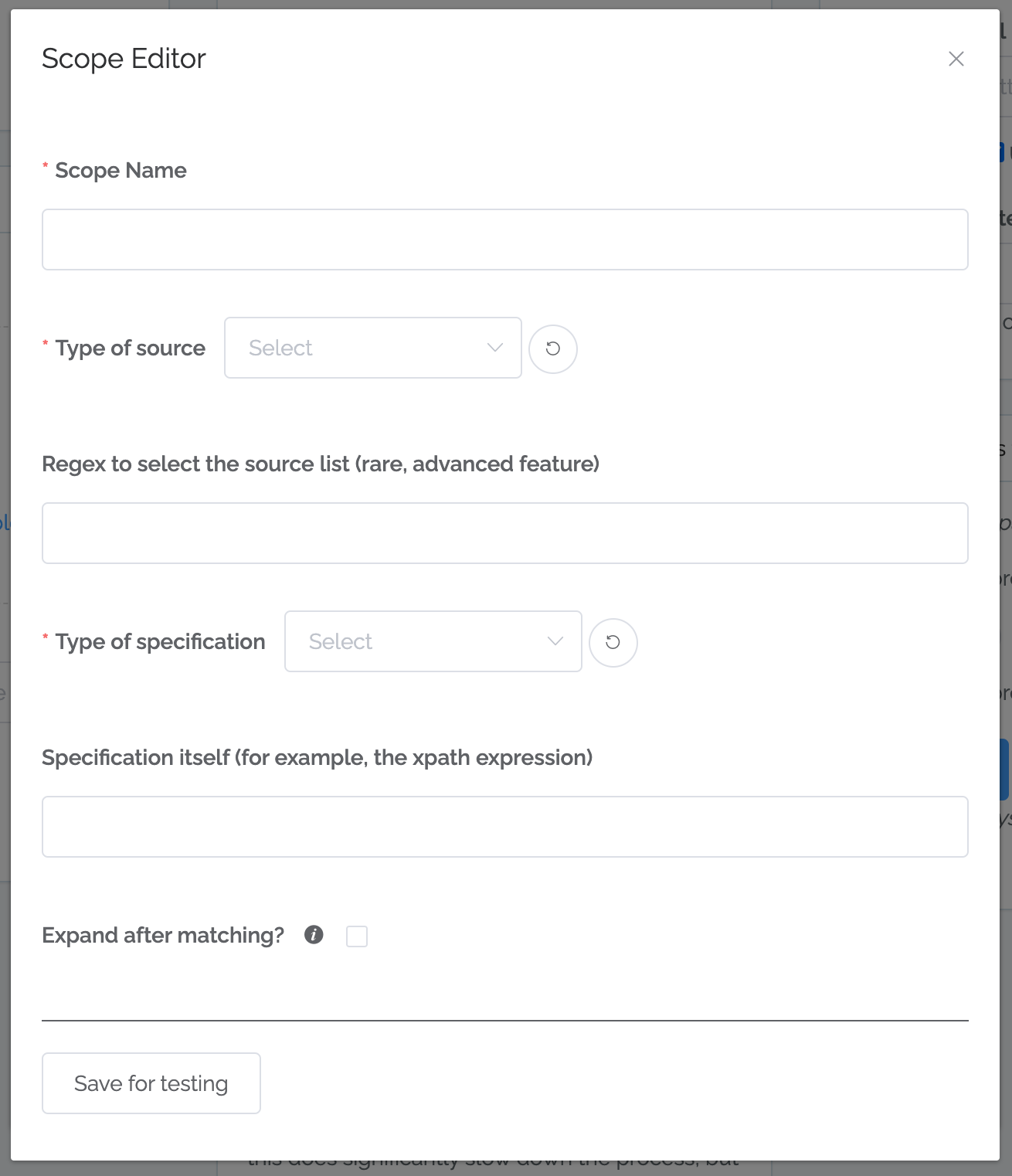
These are the items to define in a scope:
Name
Type of source. Usually you will select HTML. If you select “Field in the Inventory”, then you can scrape information out of a field.
Regex to select source. This is very rarely used. When selecting from fields, this defines which fields to select from.
Type of specification. Usually xpath. If you select Meta Tag, then you just have to put the meta tag name.
Specification itself. If using xpath, this is where you entire that.
Expand after matching? When using xpath, do you want to just select the text seen by users (what’s seen when visiting a page from a web browser) or the raw HTML? Select this button if you want the raw HTML.
Defining a pattern¶
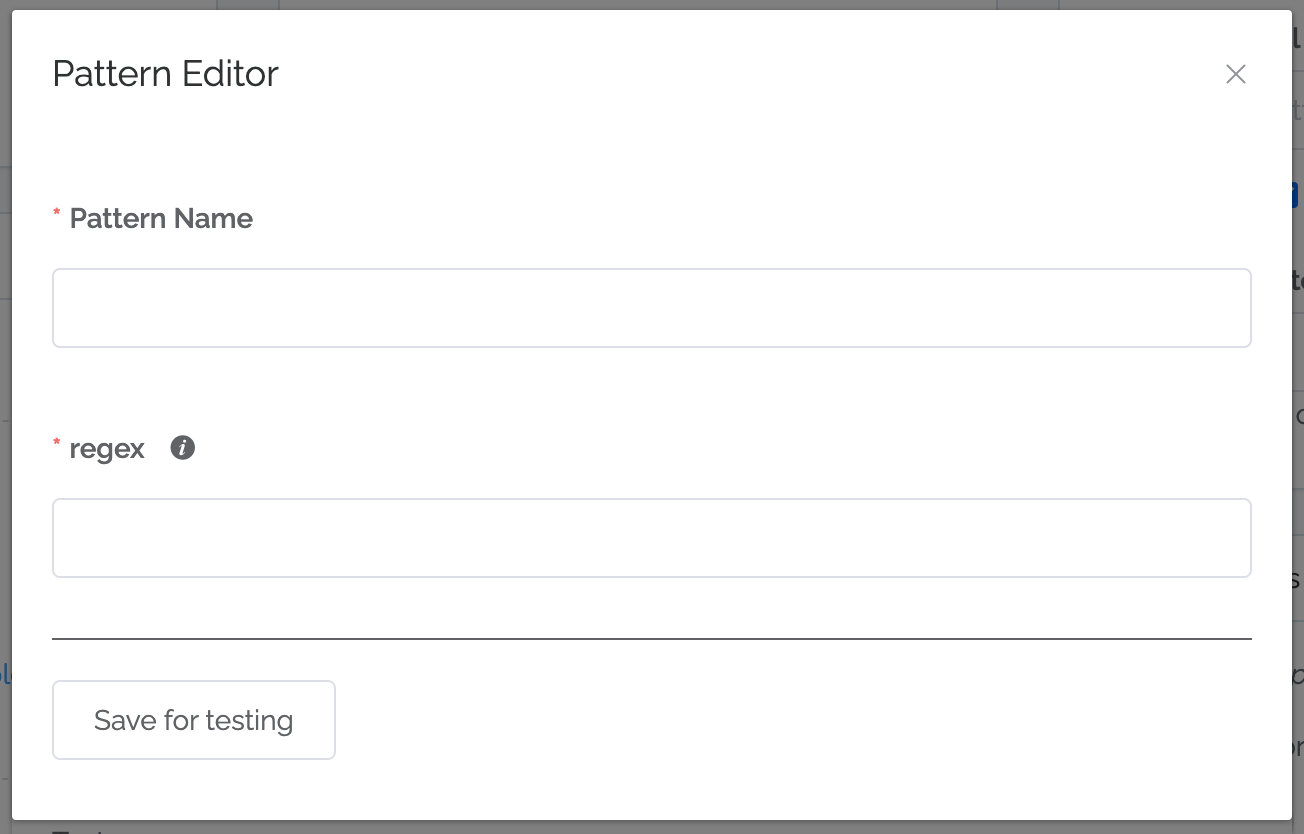
These are the items to define in a pattern:
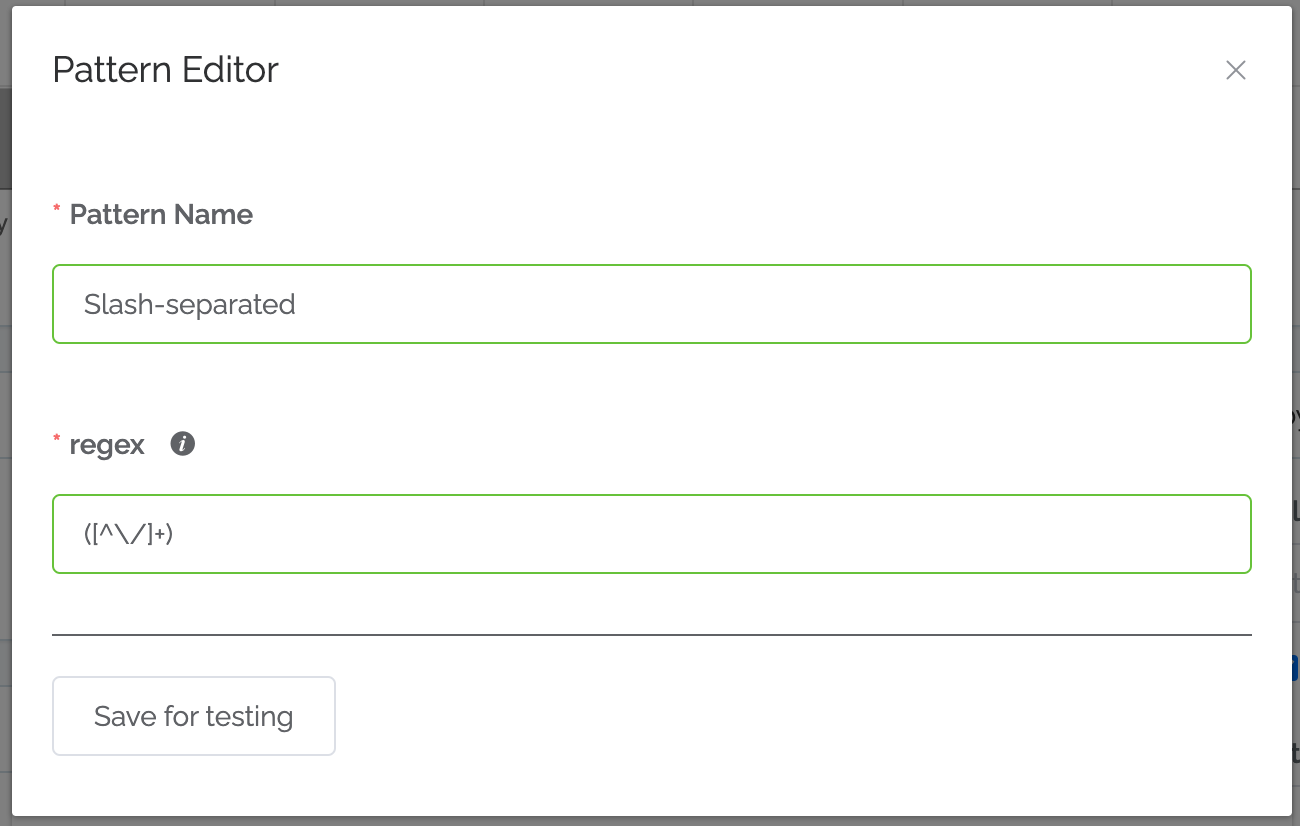
Name
Regex
Modifying existing full patterns¶
To modify an existing full pattern, click on the pencil button next to the full pattern name. From there, you can either just make the update or make the update and then scrape it.
EXAMPLE: scraping a custom pattern¶
In this example, we’ll scrape out the breadcrumb from the Adafruit site:
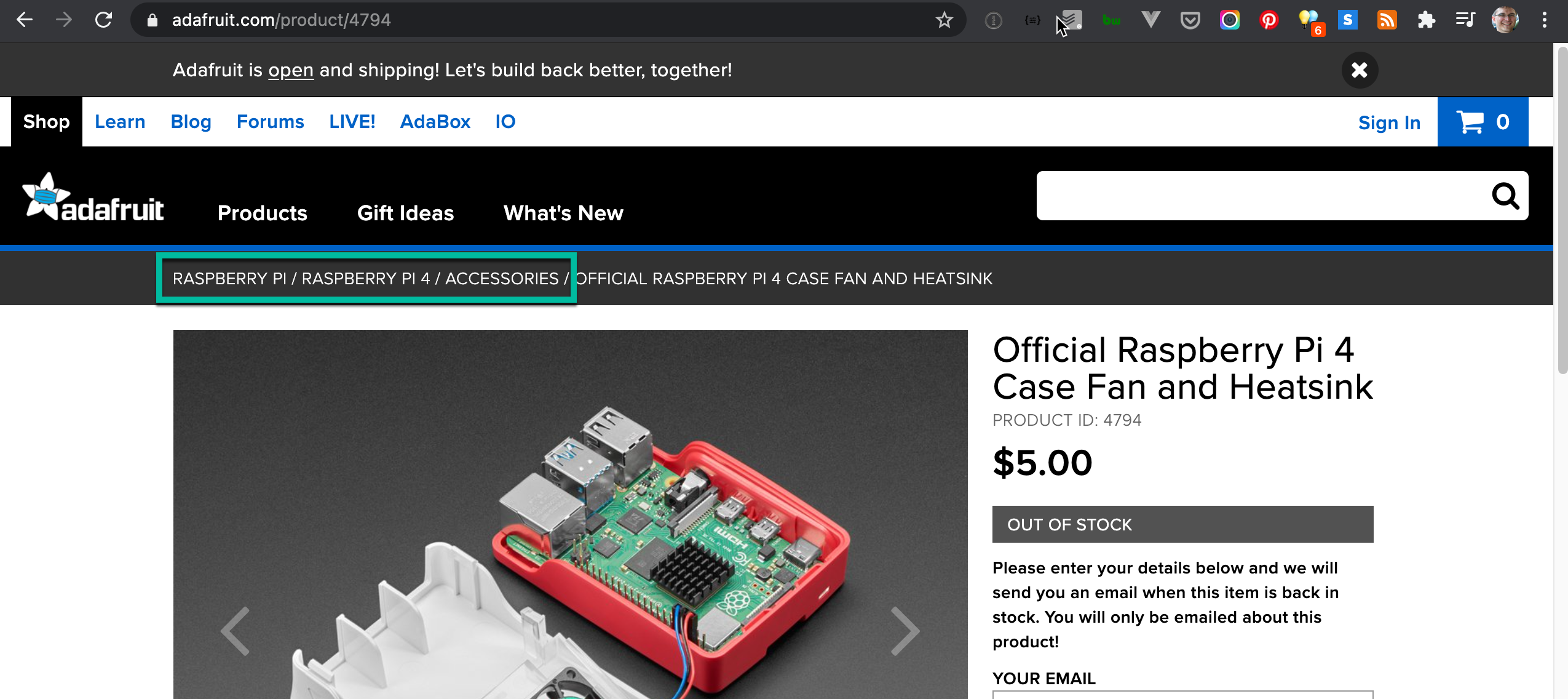
The HTML in an example page (from 15 January 2021), https://www.adafruit.com/product/4794, looks like it has a pattern we can scrape:
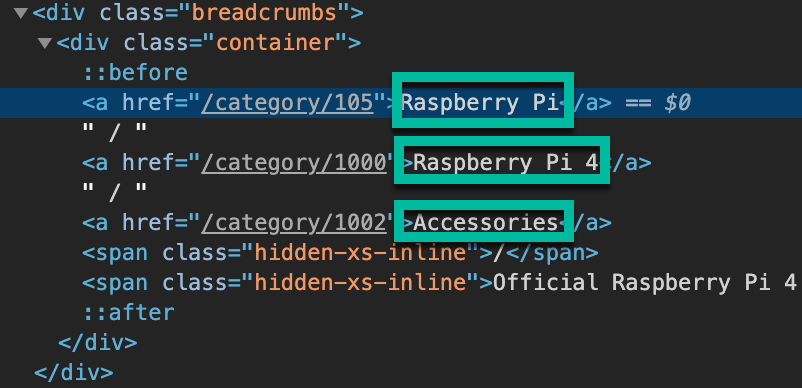
We will need to define two things to scrape this out:
Define the xpath to get the breadcrumb itself (in this case:
//div[@class='breadcrumbs']/div[@class='container'])Define the regex to break out the slash-separated items (in this case:
([^\/]+))
1. Click New Pattern on the assets page¶
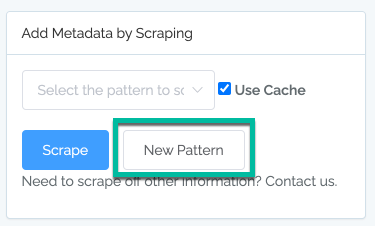
2. Click on New Scope.¶
3. Define the scope, and click “Save for testing”.¶
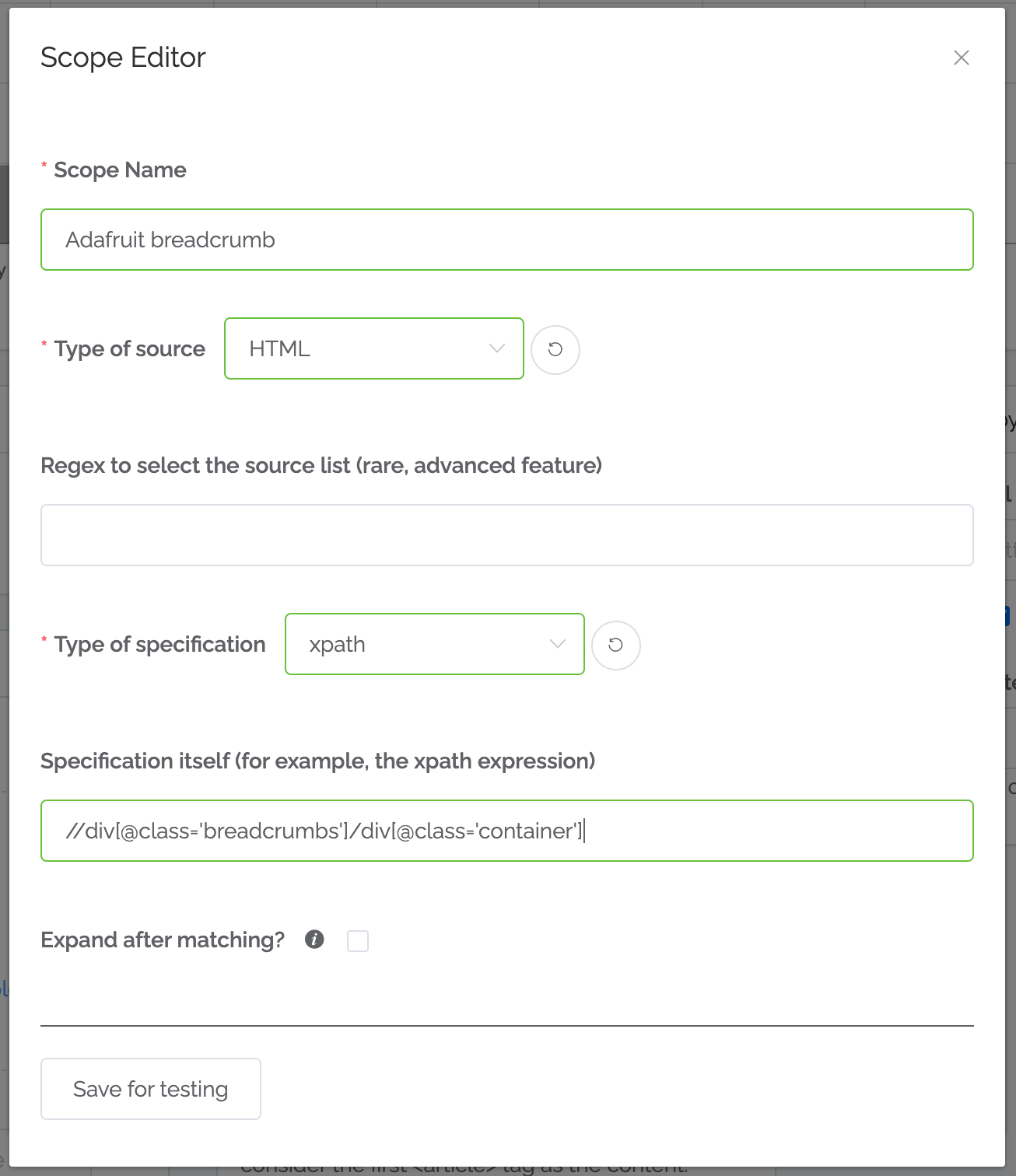
Note that in this case we do NOT want to expand after matching (we don’t want the full HTML).
4. Click on New Pattern, define the pattern, and click “Save for testing”.¶
5. Put in an example URL and click Test Against.¶
6. Ensure the example scrape worked (and repeat as needed).¶
The test results show each step of the scraping, so you can see the step where issues arose.
In this case, our scrape was successful:
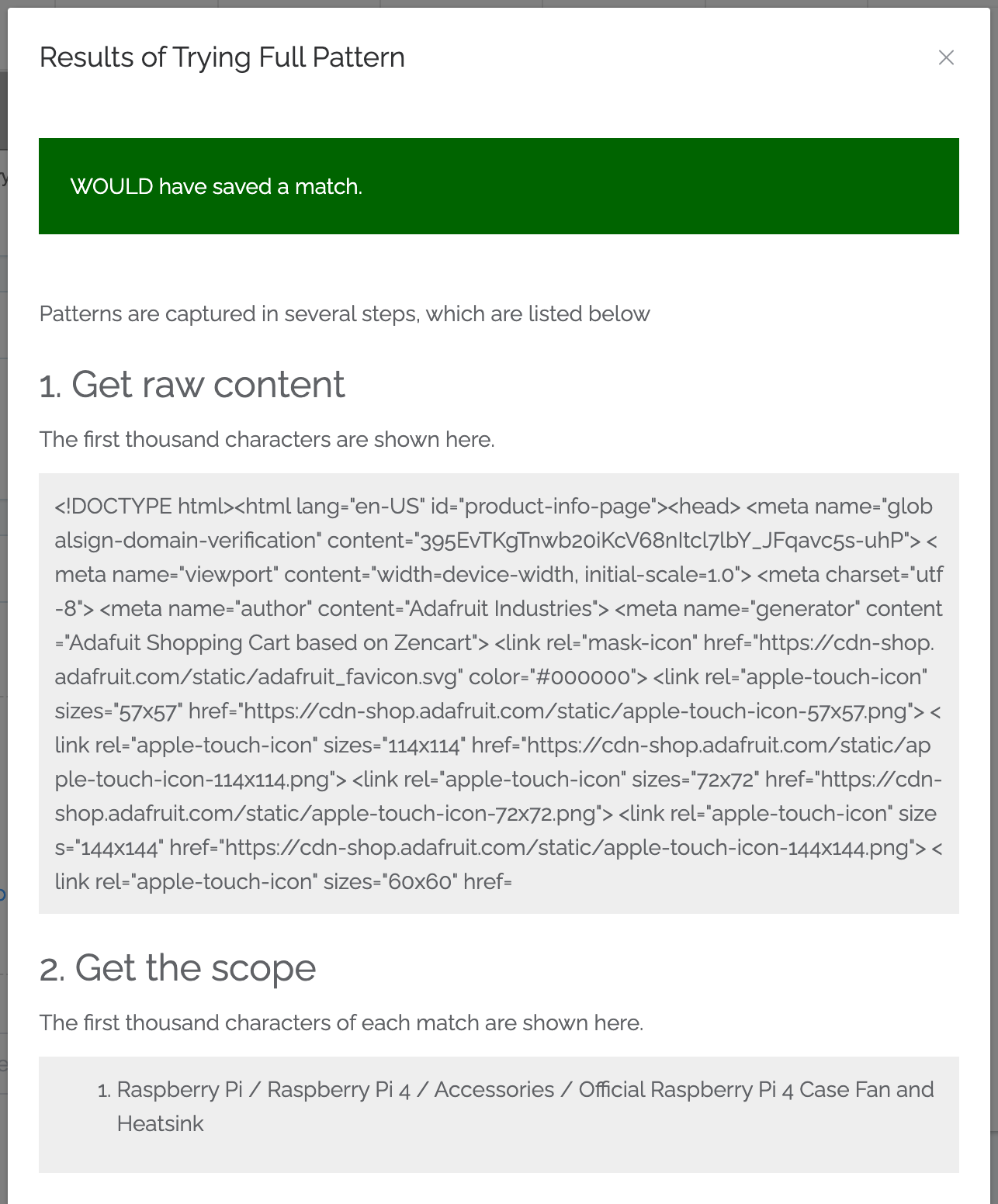
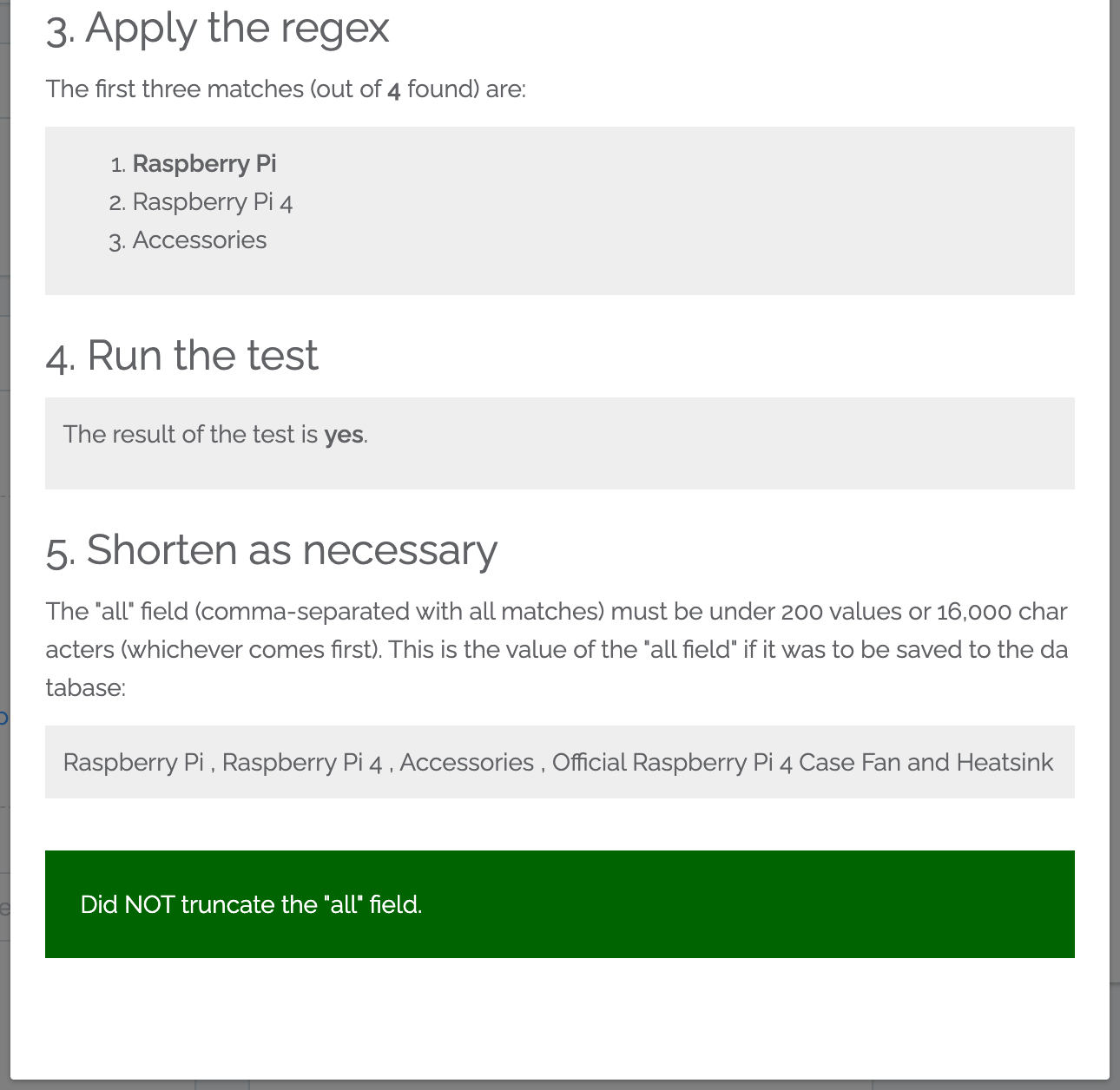
7. Close out the example results, and click on “Save and scrape now”¶

7. Wait for the scape to complete.¶
8. Go back to the assets page to start analyzing the information.¶
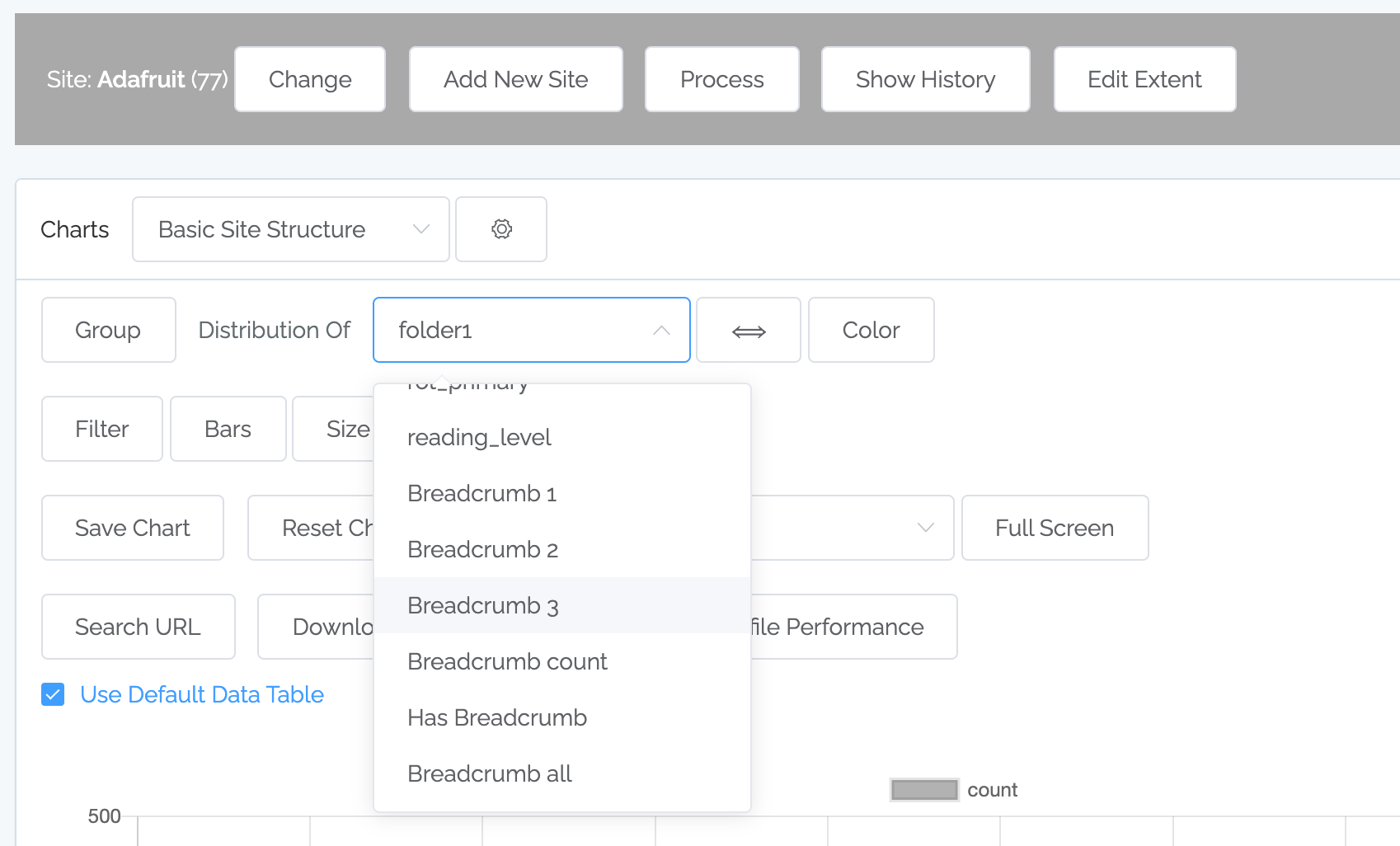
When you go to the advanced settings in charting (click on the gear next to Basic Site Structure), you will now see our new fields (for instance by clicking on the “Distribution of” pulldown):
Then you can use these fields in charting – for instance here is an example of where Breadcrumb 1 was selected:
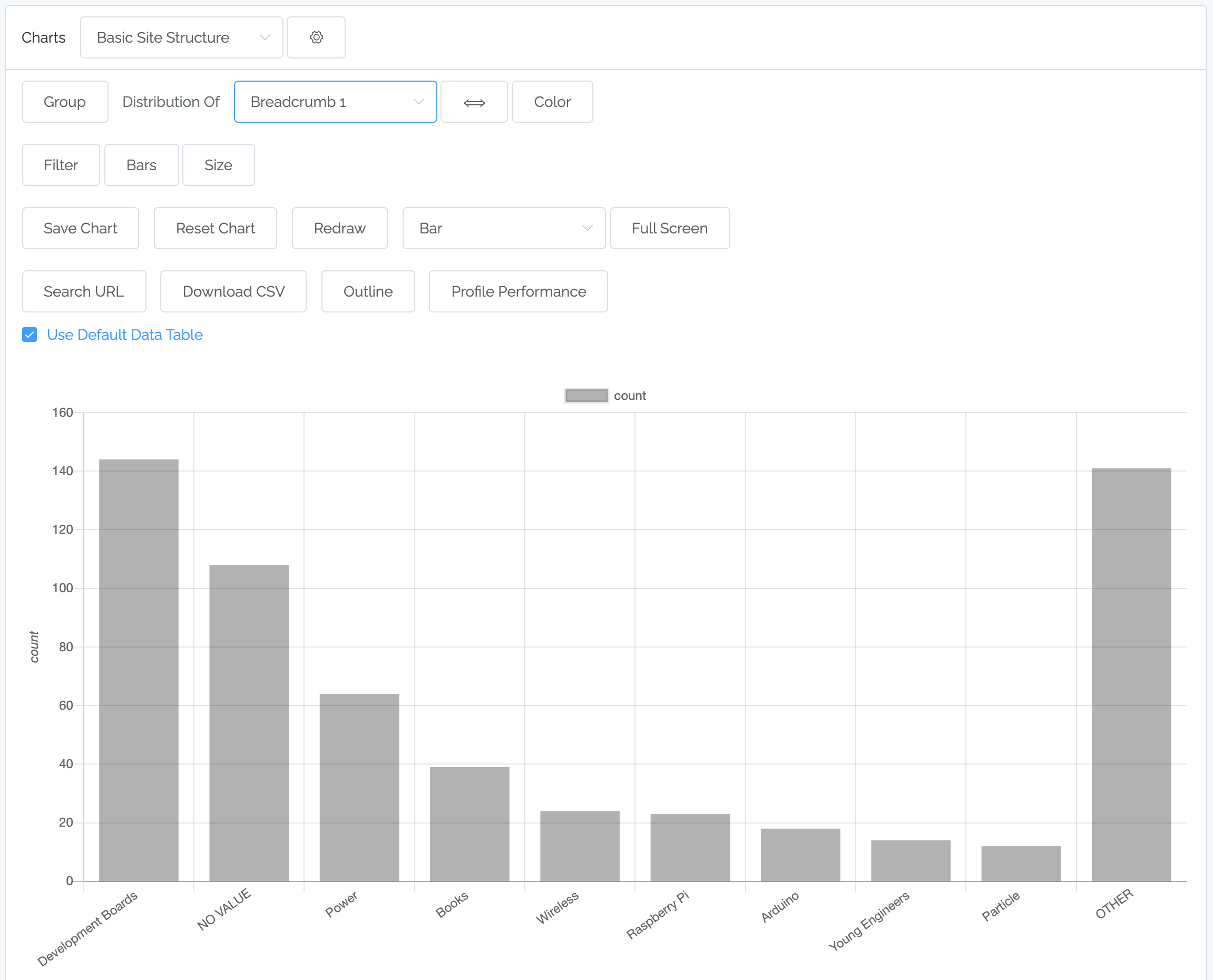
These fields can now be used in charts as well as in rules.
